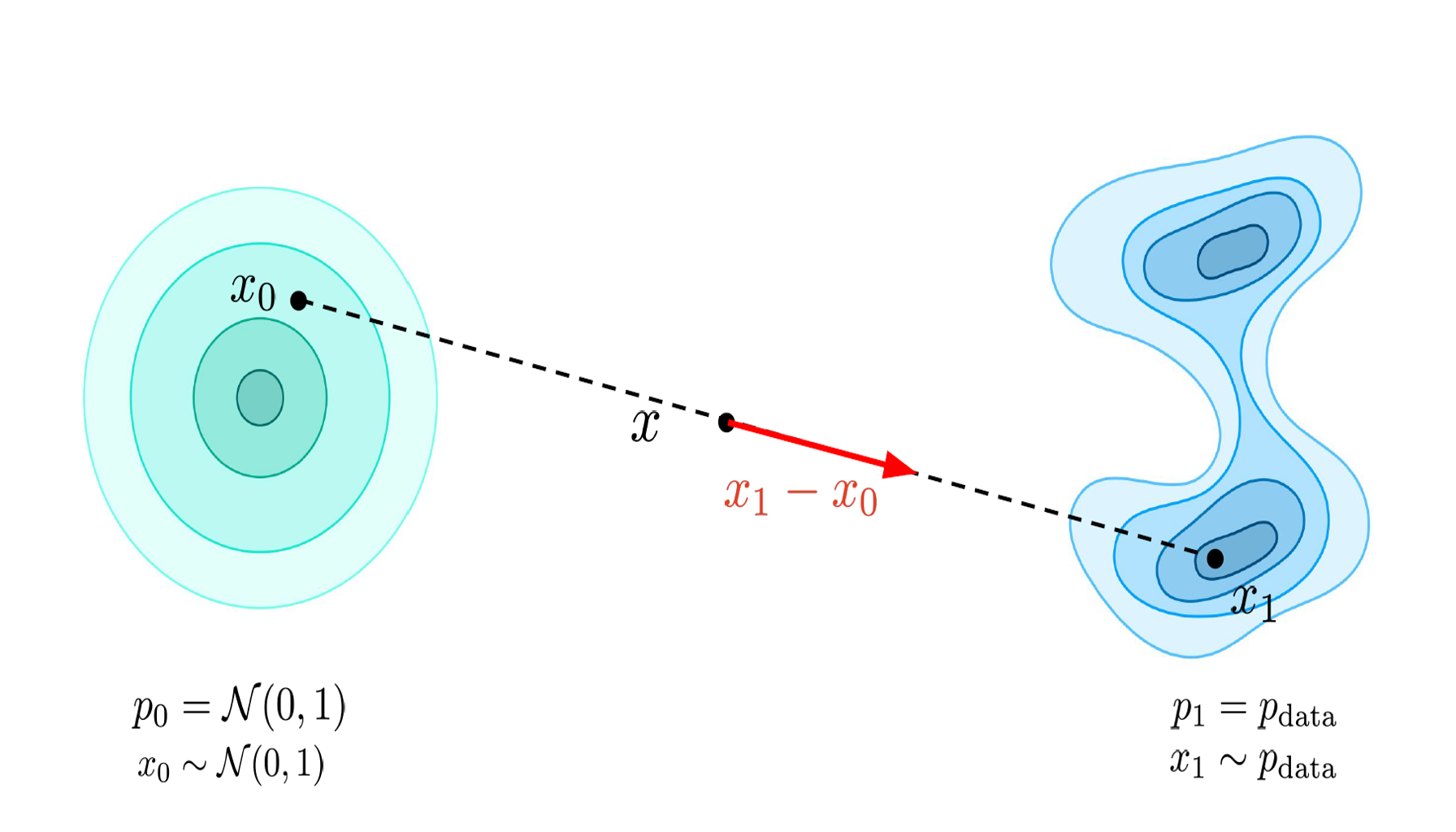
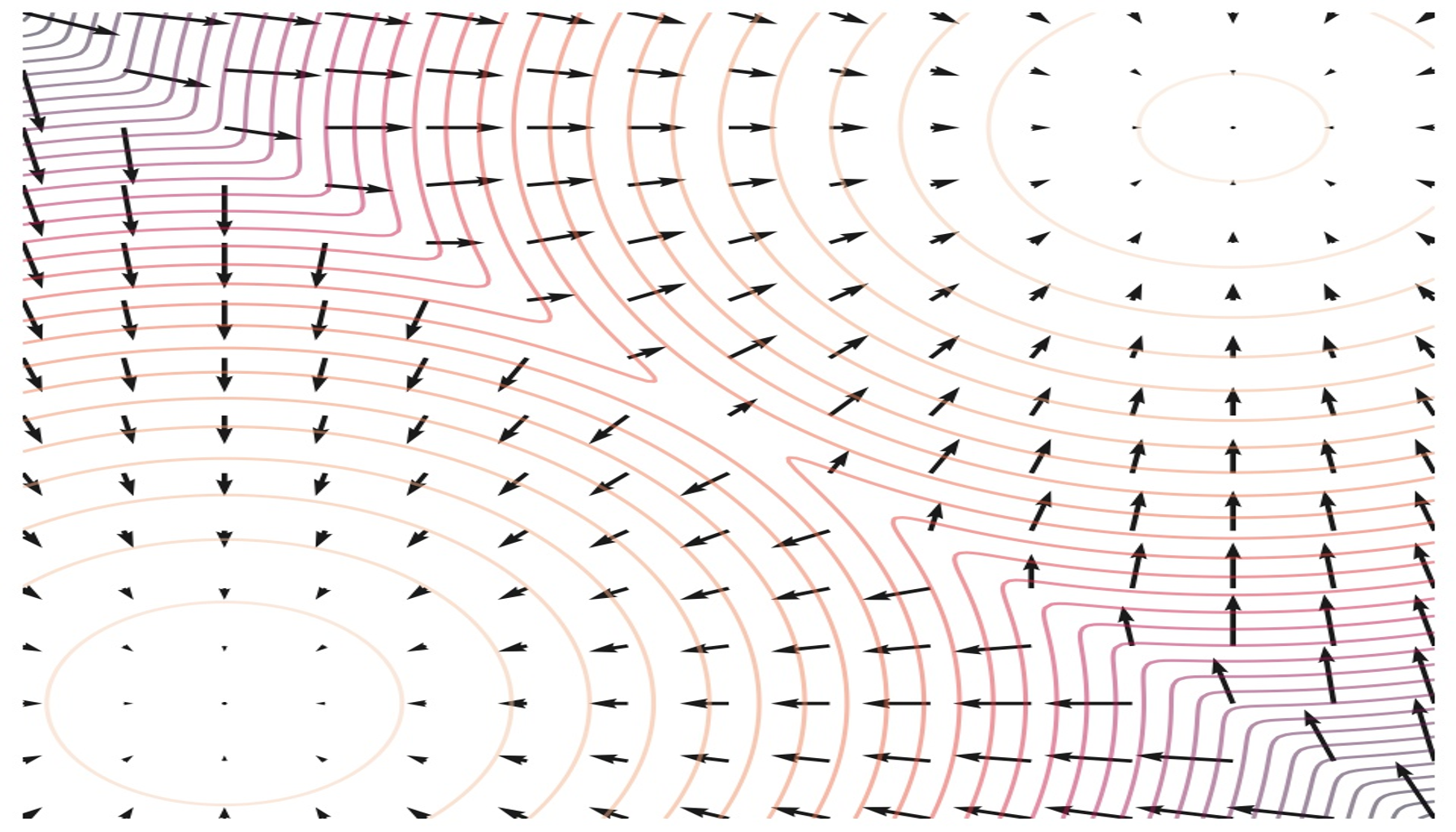
Notes on Flow Matching
Notes on Score Matching
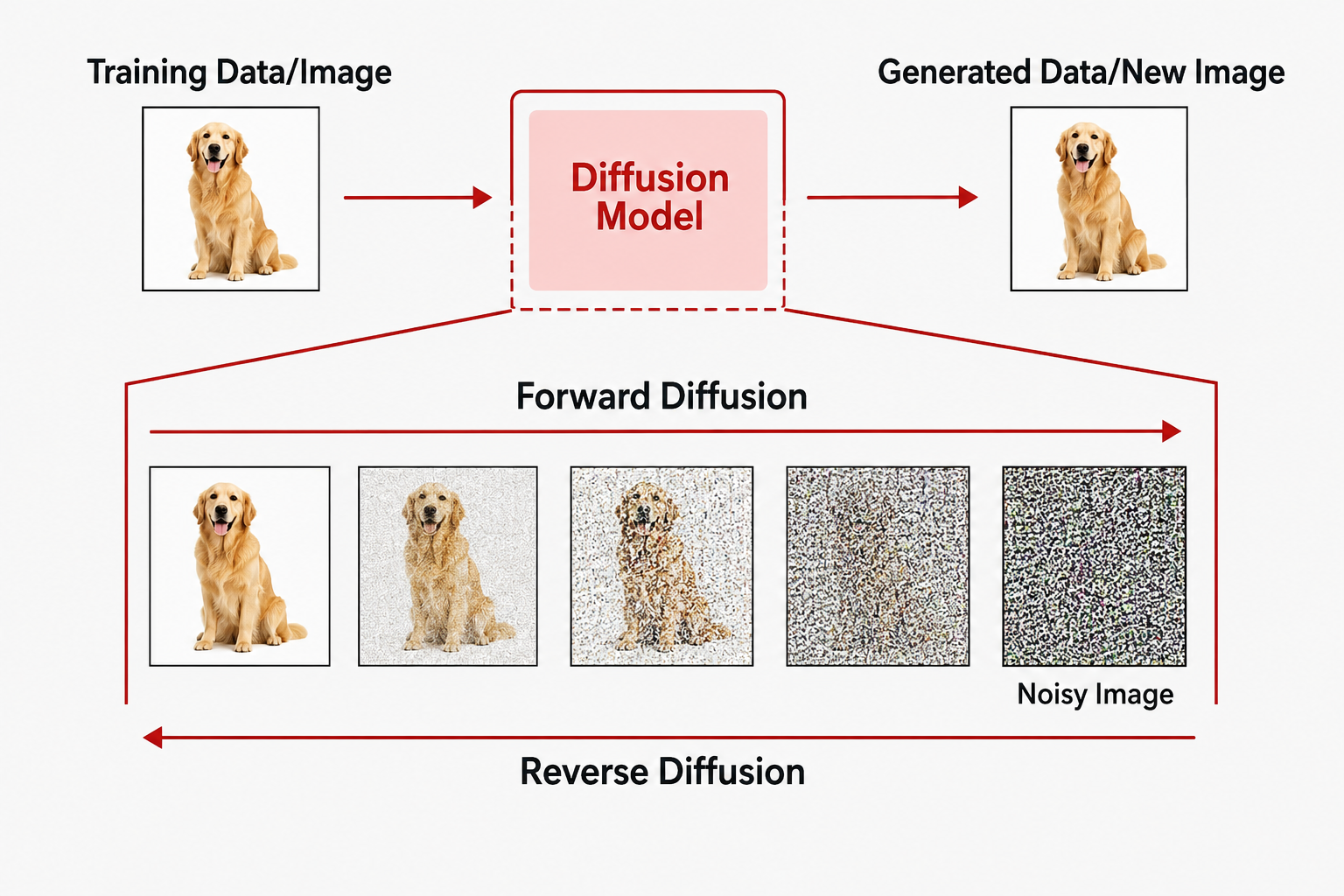
Notes on Diffusion Models
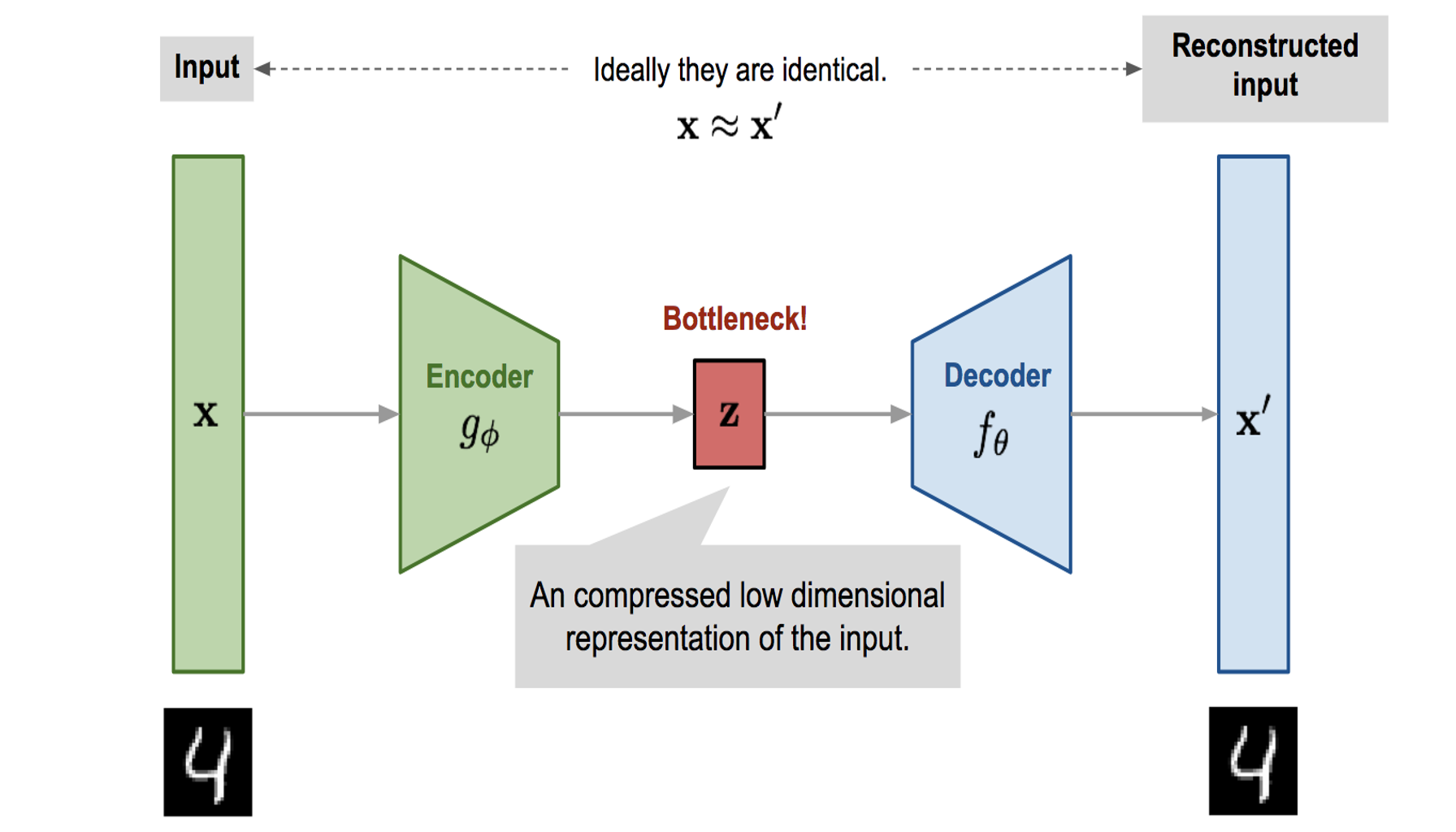
Notes on Variational Autoencoders, ELBO, and reparameterization
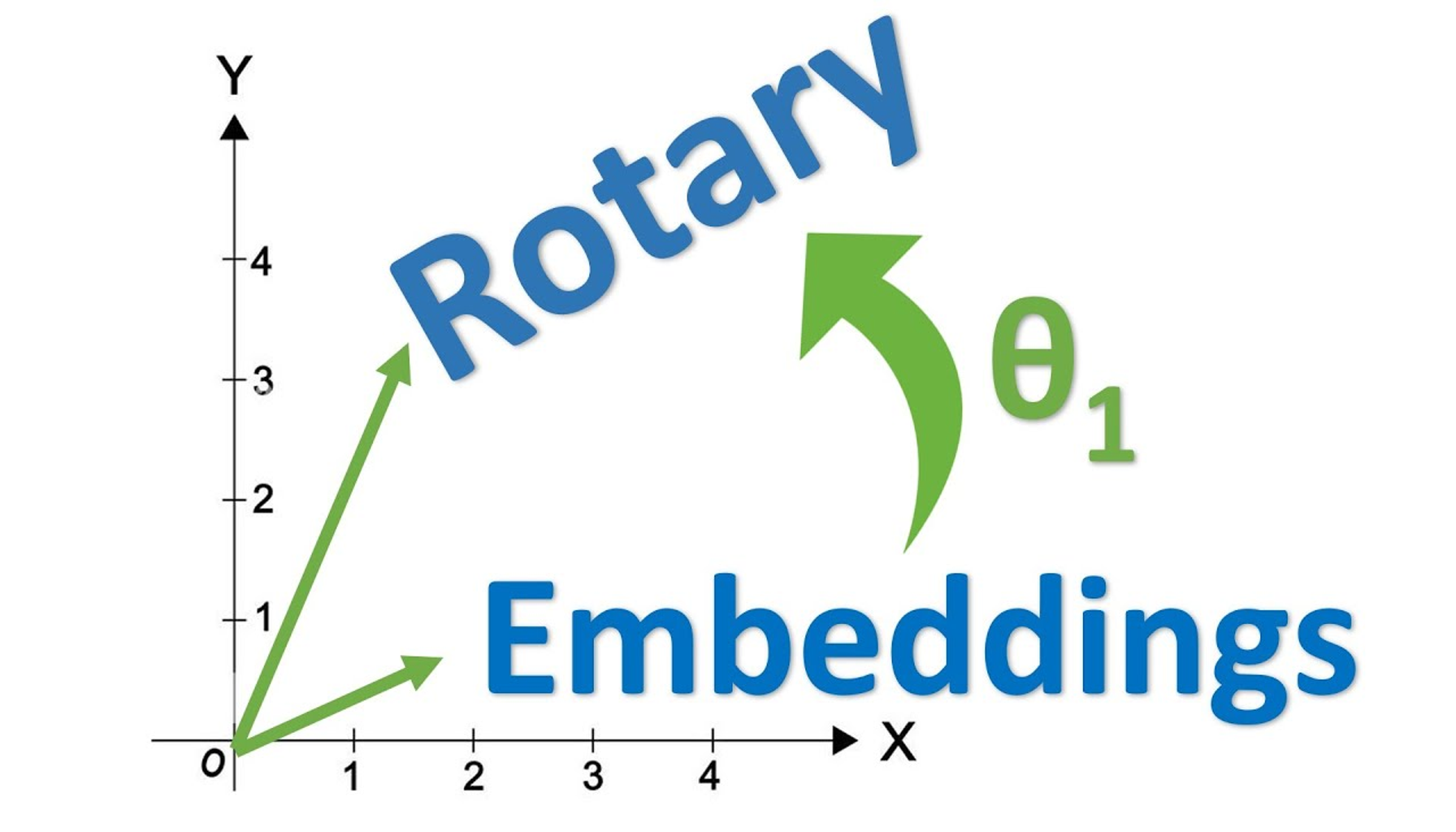
A visual and mathematical walkthrough of RoPE, relative position intuition, rotation matrices, and attention score behavior.
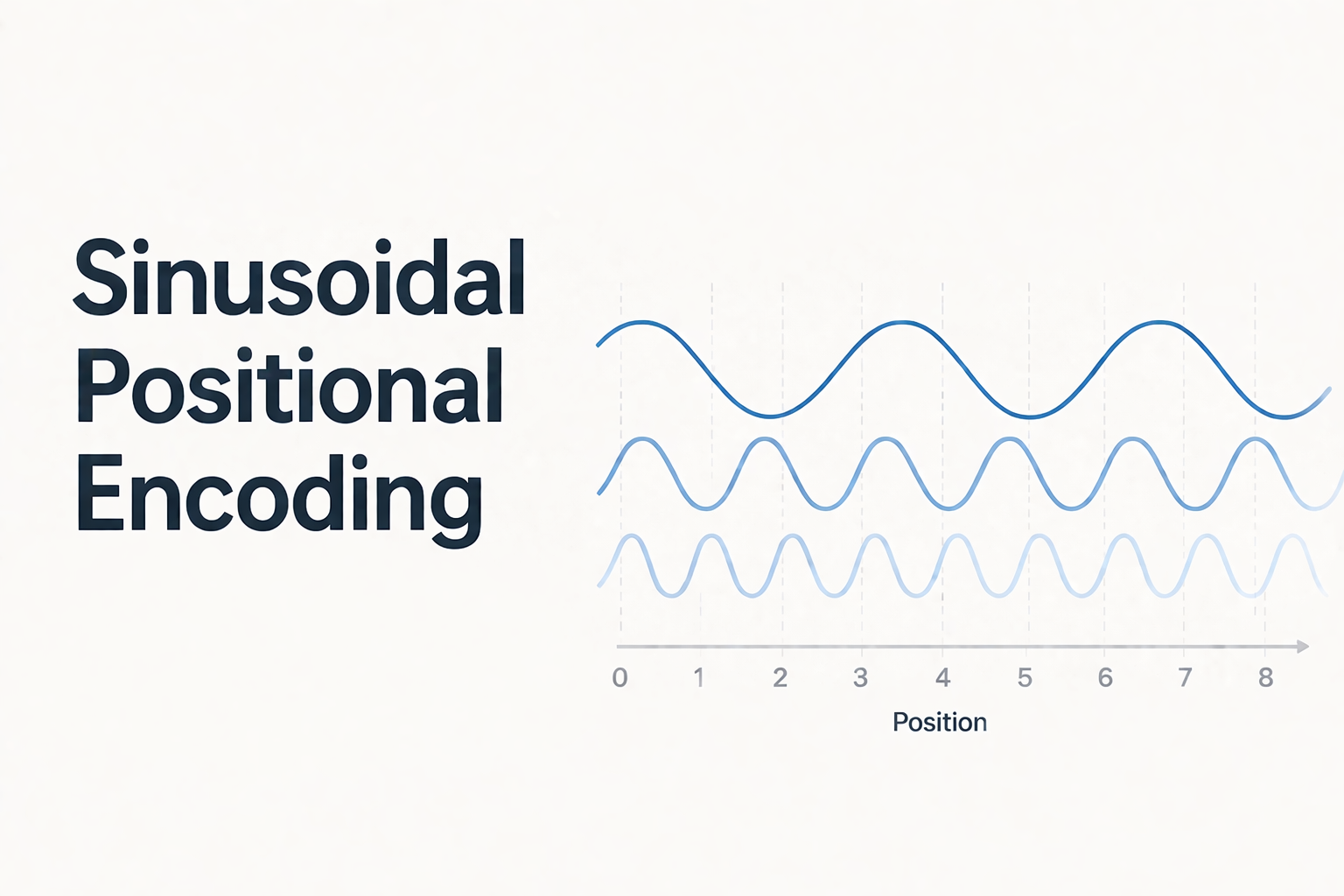
Notes on sinusoidal positional encoding, why transformers need position information, and how different frequencies encode token positions.
Work-in-progress chapter notes from AI Engineering.
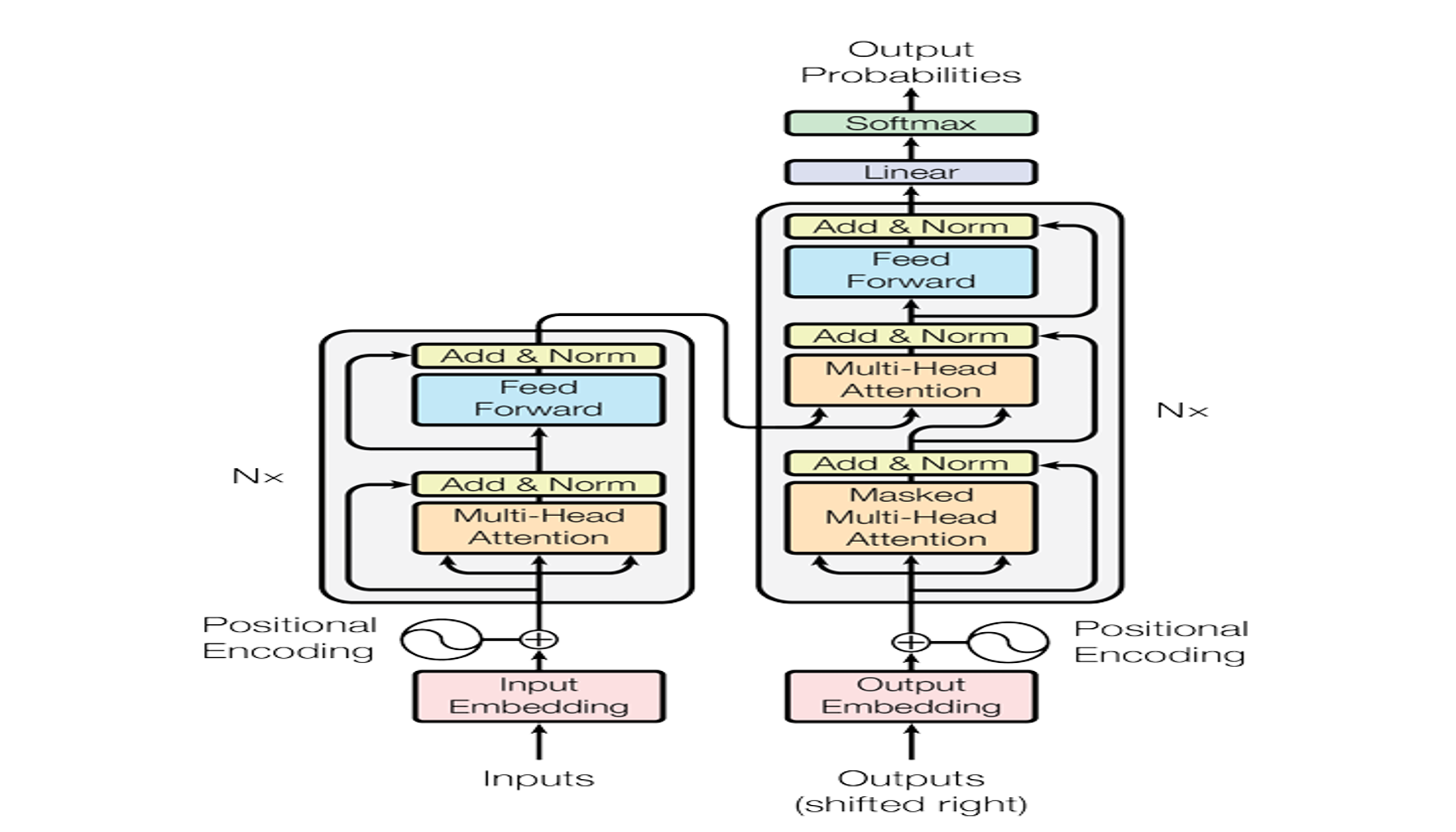
A step-by-step note on attention, scaled dot-product attention, softmax gradients, and transformer intuition.
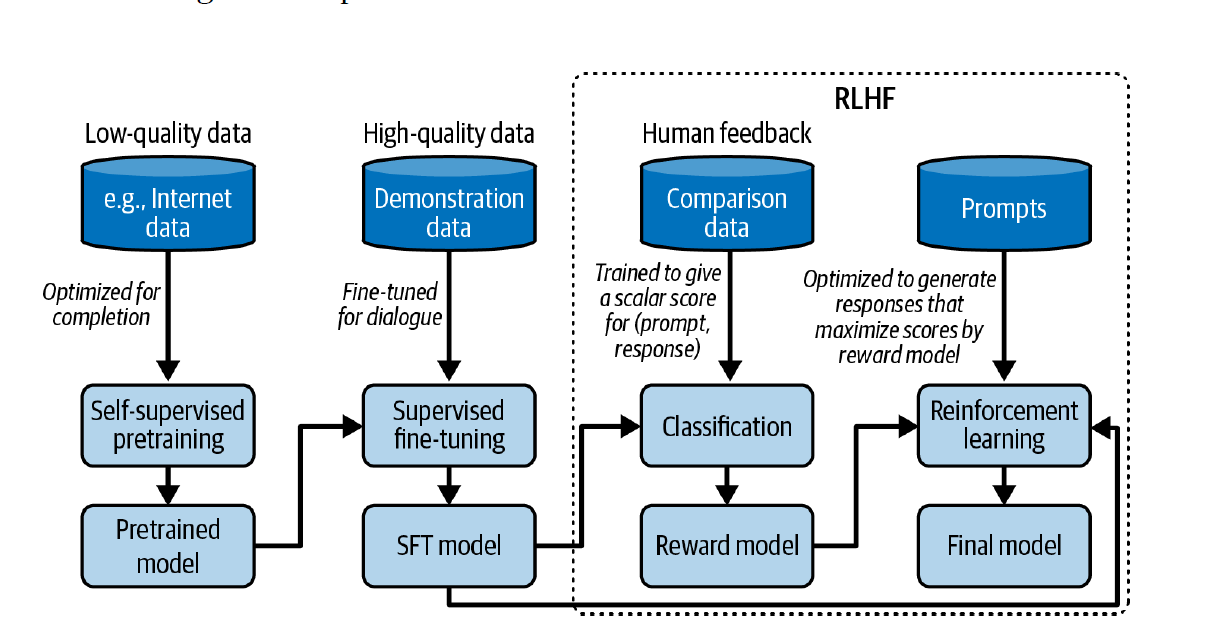
Work-in-progress chapter notes from Hands-On Large Language Models.
Chapter-wise summary notes from Meta Learning, focused on learning practice, programming habits, and deep learning growth.
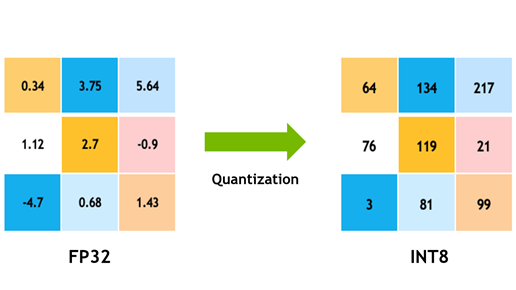
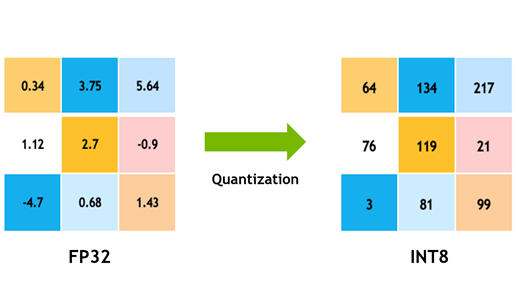
Detailed notes on quantize/dequantize workflows, quantization error, calibration, packing, and practical model optimization.
Introductory notes on model quantization, lower-precision data types, scaling, zero points, and model compression basics.