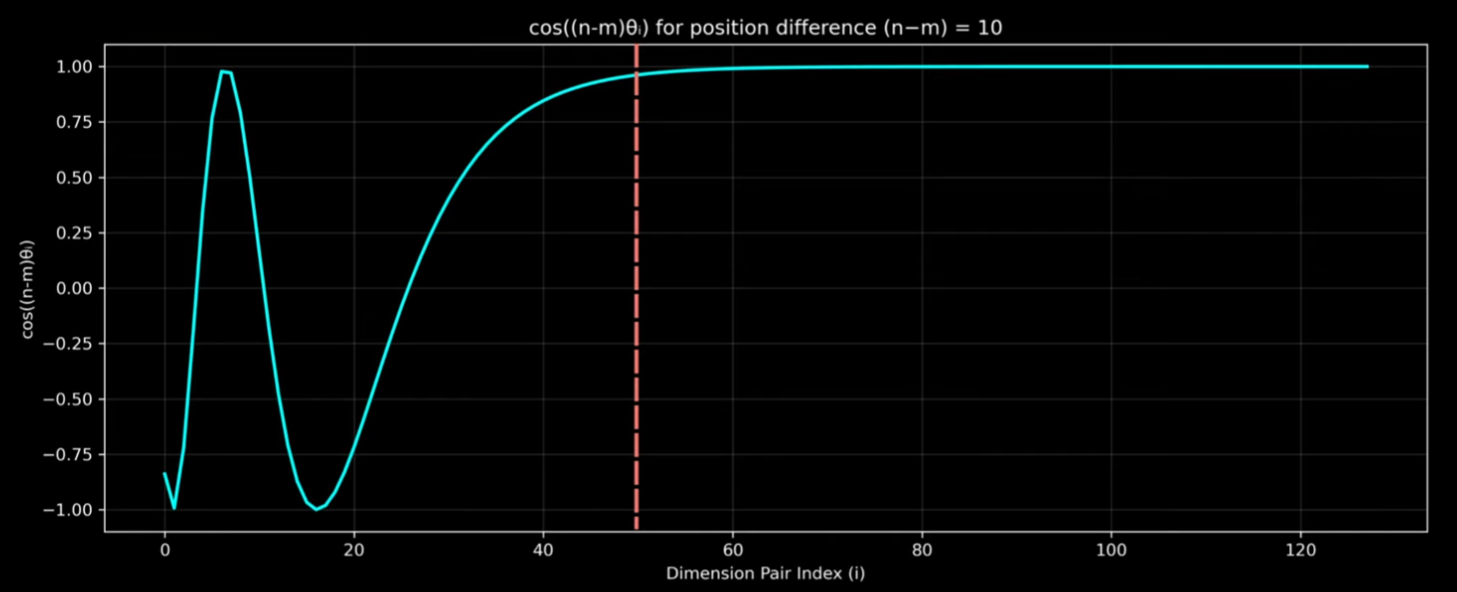
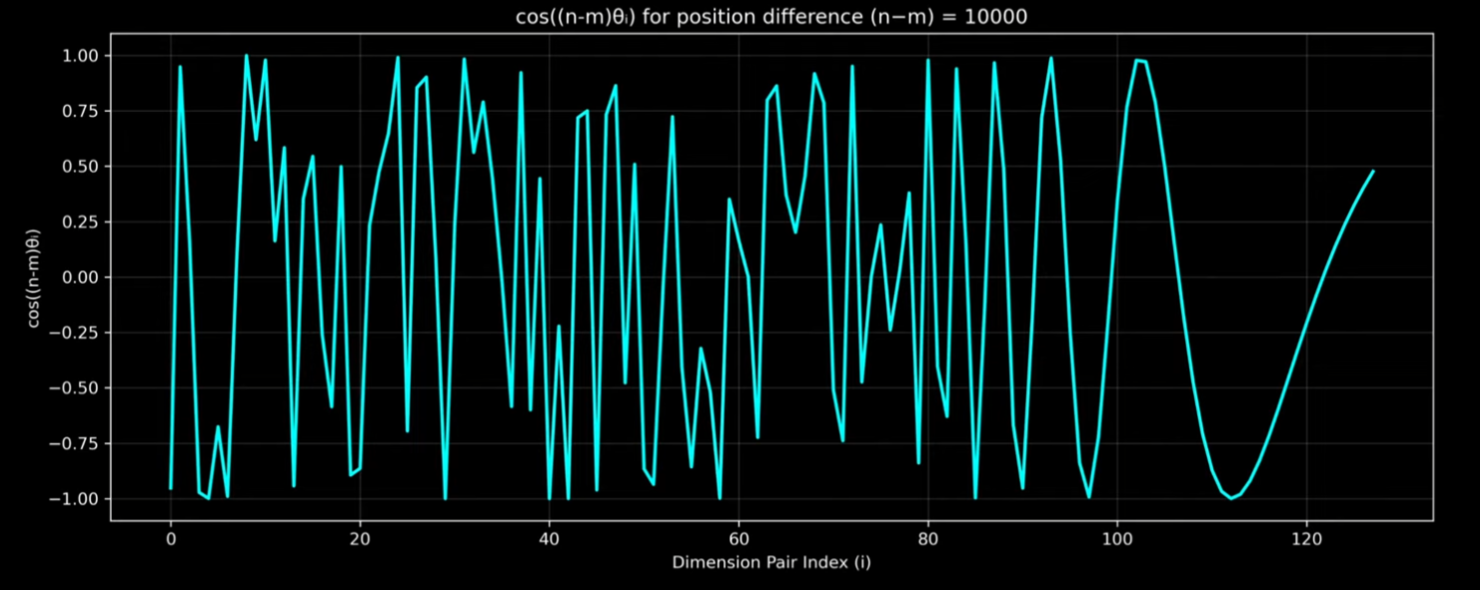
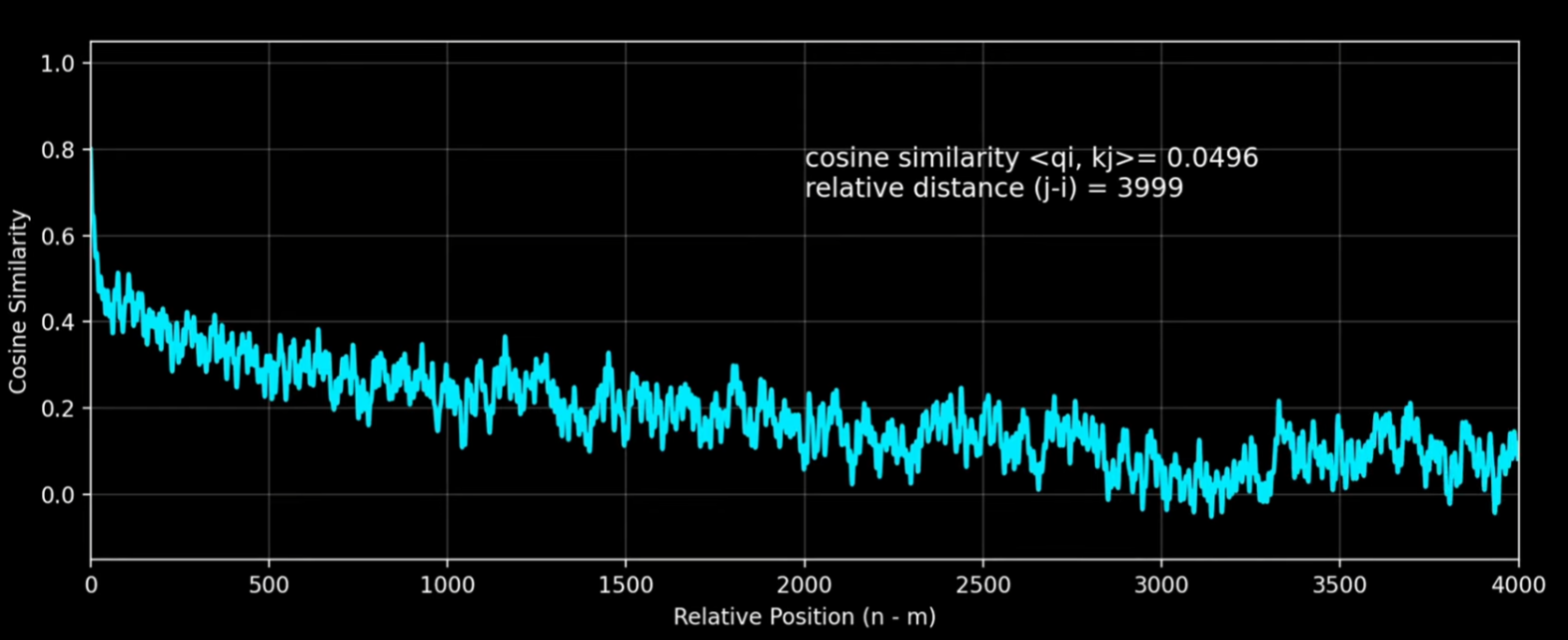
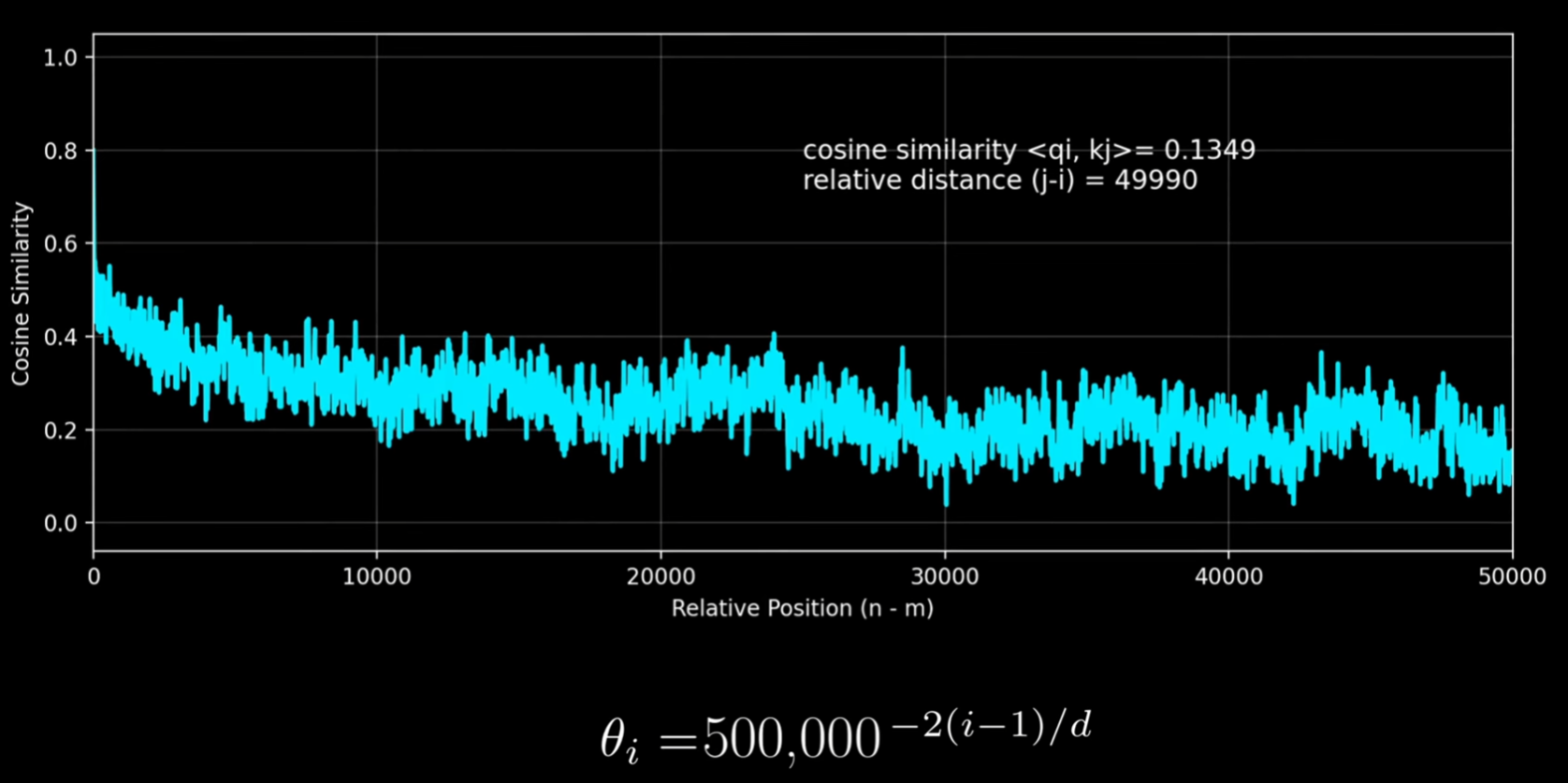
import torch
import torch.nn as nn
class SimpleAttention(nn.Module):
def __init__(self, d_model, hidden_dim):
super().__init__()
self.hidden_dim = hidden_dim
self.q = nn.Linear(in_features = d_model, out_features = hidden_dim)
self.k = nn.Linear(in_features = d_model, out_features = hidden_dim)
self.v = nn.Linear(in_features = d_model, out_features = hidden_dim)
def forward(self, x, rotary_emb):
bsz, seq_len, d_model = x.shape
query = self.q(x)
key = self.k(x)
value = self.v(x)
if rotary_emb is not None:
bsz, seq_len, d_model = x.shape
query = query.view(bsz, seq_len, self.hidden_dim//2, 2, 1)
key = key.view(bsz, seq_len, self.hidden_dim//2, 2, 1)
query = torch.matmul(rotary_emb, query).view(bsz, seq_len, self.hidden_dim)
key = torch.matmul(rotary_emb, key).view(bsz, seq_len, self.hidden_dim)
scores = torch.softmax(torch.matmul(query, key.transpose(-1, -2))/(self.hidden_dim**2), dim=-1)
final = torch.matmul(scores, value)
return final
bsz = 2
tokens = torch.tensor([[2, 3] for _ in range(bsz)])
d_model = 256
embedding = torch.randn(*tokens.shape, d_model)
RTheta = get_RoPE(tokens, d_model)
model = SimpleAttention(d_model, d_model)
out = model(embedding, RTheta)
print(out.shape)